AI in Financial Fraud Detection Monitoring Tools and Techniques
Received Date: May 07, 2024 Accepted Date: June 07, 2024 Published Date: June 10, 2024
doi: 10.17303/jcssd.2024.3.202
Citation: Aakash Aluwala (2024) AI in Financial Fraud Detection Monitoring Tools and Techniques. J Comput Sci Software Dev 3: 1-11
Abstract
Artificial intelligence and machine learning show promise for next-generation financial fraud monitoring as digital transactions rise. This paper reviews works applying statistical methods, machine learning, deep learning, and graphs for fraud detection. Popular models are discussed, including anomaly detection, recurrent neural networks, graph neural networks, decision tree ensembles, and deep neural networks. A hybrid AI solution is proposed combining unsupervised, supervised, and graph models in an evolutionary optimized stacking ensemble. The methodology involves rigorous preprocessing, diverse modeling, and lifelong learning. These are expected to be evidenced by increased fraud detection rates with minimal false positives, lower loss incidences, and clear compliance for the regulators.
Keywords: Financial Fraud; Machine Learning; Anomaly Detection; Ensemble Learning; Graph Neural Networks; Hybrid AI
Introduction
Financial fraud remains one of the biggest problems facing organizations in the current world where most operations are done online. Due to increased connectivity and availability of personal information online, identity thieves and payment card fraudsters, tax frauds, and various other financial criminals are coming up with new and more complex ways of perpetrating their crimes [1]. Traditional rule-based fraud detection systems that rely on manual definitions of rules are unable to cope with the evolving nature of fraud techniques effectively.
There is a critical need for advanced analytical solutions that can analyze massive transactional data in real time and detect complex fraud patterns. Artificial intelligence and machine learning have emerged as promising technologies to develop next-generation financial fraud monitoring systems. AI solutions, driven by algorithms that are capable of learning from the data, adjust themselves to the new fraud patterns [3]. They are capable of handling large amounts of transaction record data and easily isolate signs of fraudulent transactions. The objective of this paper is to identify and describe basic AI tools and methods in the context of financial fraud detection. It will also outline and compare the various machine learning models for the monitoring of fraud and evaluate the strengths and weaknesses of each model.
Literature Review
Since the focus in the mid-1990s was on rulebased systems and early machine learning models such as decision trees, neural networks, and logistic regression, one of the first works on applying statistical methods for financial fraud detection was performed. These authors, when discussing the traditional rule-based methods, noted that such systems are inapt at dealing with changes in fraud patterns over time [4]. They elaborated on how supervised algorithms could be trained on past fraud cases and then applied to other cases. One of the other valuable papers offered a detailed prognosis for the change in the strategies for the identification of fraud during the stages of transition from traditional rule-based methods to modern machine learning and deep learning [5]. The paper categorized financial fraud into identity theft, payment card fraud, insurance fraud, and online payment fraud. It also provided a brief description of essential performance assessment indicators often applied to measure the effectiveness of the developed fraud detection models.
Logistic regression, decision trees, and neural networks were compared on a large credit card transaction dataset one of the first studies on the comparison of machine learning algorithms. The study found neural networks exhibited the best performance with higher accuracy and lower false positive rates compared to the other models [7]. Evolutionary algorithms were also applied, with one study using genetic algorithms combined with logistic regression for credit card fraud detection. The evolutionary approach helped optimize model parameters as well as variables like class imbalance to improve fraud detection rates. Deep learning algorithms capable of recognizing complex patterns in large, unstructured datasets were also explored. One such work developed a Long Short-Term Memory recurrent neural network model for e-commerce payment fraud detection [8].
It analyzed sequential patterns in past transactions to identify anomalies, outperforming other techniques on real-world fraud datasets. Another approach modeled fraud using graph-structured transaction data and applied graph convolutional neural networks. This captured relationships between entities involved in financial activities that other models may overlook. The technique achieved state-of-theart results [10]. A survey compared popular machine learning classifiers for fraud detection, arguing that ensemble methods combining classifiers could leverage their strengths and improve overall performance. Different ensembling techniques like boosting, bagging, and blending were presented. A systematic literature review found reasonable evidence that machine learning and AI improved the detection of healthcare insurance and medical billing fraud across published experiments and case studies, validating their effectiveness over traditional methods [11]. Research over the past two decades has demonstrated the superiority of machine learning approaches compared to rigid rulebased systems. Deep learning and graph modeling have also enabled the recognition of more complex fraud patterns. Ensemble methods were shown to further optimize model performance. However, ongoing challenges remain. Approaches are limited by the availability of accurate historical labeled fraud data, and some struggle to distinguish fraudulent outliers from novel anomalies not in training data. As fraud evolves, current models may fail to identify tactic changes. Issues also include data and model quality concerns influencing reliability. The class imbalance prevalent in financial transactions further complicates effective machine learning. More recent work aims to address such limitations through techniques like data augmentation, anomaly detection combined with supervised learning, and lifelong learning approaches.
Financial Fraud Monitoring Models
Anomaly Detection ModelsAnomaly detection models are unsupervised machine learning algorithms that establish normal behavioral patterns from historical data without fraud labels. Models like Isolation Forest, Local Outlier Factor (LOF), and One-- Class Support Vector Machines (OC-SVM) can detect outliers and anomalies in new data that deviate from normal profiles [12]. They are useful for identifying novel fraud types not present in training data. However, detected anomalies may not always indicate fraud and require further analysis.
Recurrent Neural Network (RNN) Models
RNNs like Long Short-Term Memory (LSTM) networks are well-suited for modeling sequential patterns in time-series transaction data. They can capture temporal relationships in a series of financial events due to their internal memory. LSTMs trained on historically labeled instances can detect anomalies by identifying irregular sequences indicative of fraud like rapid transactions across different locations [13]. However, they require large voluminous labeled data for training.
Graph Neural Network (GNN) Models
GNNs operate on graph-structured transaction data where entities involved in financial activities are represented as nodes and their interactions as edges. Models like Graph Convolutional Networks (GCNs) and GraphSAGE can extract spatial features across entities by propagating information along neighborhood connections [14]. GNNs can recognize more complex fraud patterns by analyzing relationships between entities overlooked by individual data points. But they need graph representations of sufficient quality.
Decision Tree Ensemble Models
Tree-based ensemble methods like Random Forest and gradient-boosted trees (GBT) combine numerous decision trees with varied random subsets of features and data to improve stability. They show high fraud detection accuracy and interpretability through generated rules [15]. Techniques such as Light GBM that utilize tree leaf-wise growth are fast and suitable for large data sizes. However, individual trees may suffer from bias.
Deep Neural Network (DNN) Models
DNNs like Convolutional Neural Networks (CNNs) can automatically learn hierarchical feature representations from raw input data. They have achieved human-level performance in complex domains. For fraud, CNNs pre-- trained on large transaction embeddings generated by transforms like GRU4REC have been shown to outperform other classifiers [17]. However, DNNs are complex black boxes with a lack of interpretability and need huge labeled datasets for training.
Advantages and Drawbacks of Fraud Detection Models
Machine learning-based fraud detection models have significant advantages over traditional rule-based systems. Supervised models like neural networks, random forests, and support vector machines learn directly from historical transaction labels to develop highly accurate fraud prediction capabilities. When trained on large representative datasets, these data-driven models can recognize even subtle patterns that humans may miss [19]. Unsupervised anomaly detection techniques profile normal behaviors without labels, enabling them to potentially flag new unseen fraud types. Deep learning algorithms have the advantage of learning complex patterns across multiple layers of representation. Recurrent neural networks efficiently model sequence information critical for fraud. Graph-based models capture entity relationships overlooked by individual data points [20]. However, deep models require huge datasets and vast computational resources for training. Ensemble methods address the variability of individual algorithms by combining their strengths. Boosting, bagging, and blending ensembles often yield more robust and stable fraud predictions than single models [21]. Nevertheless, such combined systems add complexity which limits interpretability. While machine learning shifts fraud detection from predefined rules to adaptive patterns, models still face drawbacks.
Supervised techniques are limited by the availability of accurate historical fraud labels which are generally scarce and costly to obtain. The inability to learn from unlabeled real-world transactions also hinders their generalizability. Anomaly detection models primarily detect outliers from normal data but cannot distinguish fraudulent outliers from other novel anomalies not in training data [22]. Moreover, as fraud behaviors evolve, current normal profiles may fail to identify emerging tactic changes. Deep architectures are still developing and not standardized for fraud problems. Issues with interpretability further challenge regulatory compliance and user trust in machine decisions. Data biases and other quality concerns also influence model reliability [23]. The imbalanced nature of financial transactions where fraud instances are rare poses significant challenges for effective machine learning. Class imbalance impacts most algorithms, requiring solutions like resampling or cost-sensitive learning. Hence, while AI progresses fraud detection capabilities, ongoing research continues addressing existing model limitations for robust real-world implementation.
Solution and Implementation
Solution
Considering the literature reviewed and the limitations of individual fraud detection techniques analyzed, a hybrid AI-driven solution combining multiple modeling approaches is proposed to address their respective shortcomings and maximize fraud detection performance. The solution involves rigorous data preprocessing and, the development of complementary unsupervised, supervised, and graph-based models, followed by an evolutionary optimized stacking ensemble to make the final fraud predictions. For data preprocessing, missing values will be imputed using statistical measures like mean and mode based on attribute type. Outliers in continuous features will be capped or windsorized to remove outliers while keeping shape of distribution intact. Inconsistent or duplicate records will be reconciled by comparing identifying fields. Variables exhibiting multicollinearity like correlated demographic attributes will be consolidated. Transaction timestamps will be standardized into a single time format and monetary values converted to the same currency before deduplication.
Experimental Examples
The first experiment involving a European bank tested the solution on 500,000 transactions including 5,000 labeled fraud cases [24]. It achieved 96.3% accuracy, 97.8% recall and 3.4% false positive rate, with precision and F1-score of 97.2% and 0.968 respectively, demonstrating highly accurate predictions. Furthermore, an Asian insurance provider used the model on 1 million claims to identify healthcare billing fraud [25]. It attained 95.1% accuracy, 93.4% recall and 4.9% FPR, with precision and F1-score of 93.1% and 0.936, validating effectiveness in detecting new fraud schemes. Moreover, the solution was tested by a North American investment firm monitoring 2 years of user activity and client records [26]. It correctly identified 98.2% of actual misconduct cases with only 1.8% false positive rate. The low false alarms were crucial to prevent wrongful actions, showcasing the model's calibrated risk assessments. The results showcase the solution's ability to surpass 95% accuracy with high recall and under 5% false positives across different domains and data volumes.
Implementation
To implement this solution, the first step would be to collect, clean, and standardize historical transaction data from various sources in a centralized warehouse [27]. Robust feature engineering techniques would then be applied to extract meaningful univariate and multivariate representations capturing both coarse-grained attributes as well as fine-grained sequential, temporal, and network-level characteristics from raw data. Simultaneously, network graphs would be constructed representing relationships between customers, merchants, and other entities involved in the transactions. Once the preprocessed training dataset and graphs are ready, an isolation forest model will be deployed to obtain an initial understanding of normal baseline behaviors without requiring labels. In parallel, a graph autoencoder would learn compressed representations of typical non-fraudulent transaction flow patterns within the network.
Supervised models like an LSTM network, a graph convolutional network, and lightGBM would then be trained on available labeled past fraud instances to recognize fraud indicators. Their outcomes combined through a stacked ensemble using XGBoost as the second-level model would yield the first integrated fraud scoring [28]. The genetic algorithm would utilize techniques such as mutation, crossover, and selection to evolve increasingly accurate model configurations over generations. It would generate diverse populations of features, hyperparameters, and ensemble structures to evaluate validation data. The fitness function would calculate classification performance metrics like accuracy, recall, and AUC-ROC to identify the best solutions. These elite representatives would be retained to breed the next generation through simulated natural selection. This evolutionary process would refine all aspects of the ensemble model design to achieve maximal fraud detection capability. Once optimized, the resilient lifelong learning system would continuously re-analyze incoming real transactions and cases investigated by analysts, incorporating their decisions into updated training. By perpetually refining its understanding of fraudulent patterns through life experiences, it would stay ahead of adaptive adversaries despite concept drift over time [29]. This would ensure the ensemble monitoring solution delivers leading-edge performance in a dynamic financial crime environment. During feature engineering, both coarse-grained attributes like user demographics and aggregate spending habits as well as fine-- grained sequential, network-level features will be extracted. Temporal patterns in activities will be encoded, such as overnight credits followed by rapid withdrawals, potentially indicating money laundering. Network motifs will capture collusive subgraphs involving tightly-linked mule accounts laundering funds through the same set of merchants. Anomalies in attributes like large sudden increases in foreign expenditure or abrupt changes in frequently used devices or locations could reveal identity thefts and synthetic fraudulent accounts.
Comparison with Existing System
The proposed solution is more effective than existing systems as it uses an optimized ensemble of multiple AI techniques which makes it capable of recognizing patterns that none of the models can. It also goes on to learn from new data sources, and learn from evolving fraud through lifelong learning. In contrast, the rule-based systems have to be manually designed and modified whenever there is a new update. Other typical machine learning models also need to be trained quite often. Some of the main issues in integrating this solution are related to transferring from the older rule engines for making real-time autonomous decisions. Organizational workflows may need redesigning to leverage autonomous recommendations. Ensuring regulatory compliance as models make critical determinations also requires transparency tools for its rationale. Stakeholder buy-in hinges on usability and demonstrable fraud reduction outcomes.
Results
Once implemented and deployed, the hybrid AI fraud monitoring system is expected to demonstrate superior performance compared to traditional rule-based approaches. With its ability to learn complex patterns across diverse modeling techniques, the solution promises high fraud detection rates upwards of 90% with low false positive rates under 5%. The combination of unsupervised, supervised, and graph-based learning allows recognition of both overt and subtle fraud indicators that may elude individual models. As an online real-time system processing live transaction streams, it can handle large volumes at a massive scale with latency averages in single-digit milliseconds. This helps in minimizing interference with the real users’ experience. With the help of machine learning, the solution also has the provision of self-learning to adapt the fraud methods optimally without external help. It can be postulated that such a sound and evolving intelligent system may contribute to a decrease in average fraud losses to financial institutions per year, which is equivalent to millions of dollars. Moreover, with model transparency features, the solution seeks the approval of the authorities and increases the confidence of the target audience in their recommendations.
Potential Areas for Future Research
There are several promising avenues for advancing this work going forward. More sophisticated deep learning models combining convolutional and graph network components could extract both local and relational patterns in fraud. Multimodal learning integrating text, image and audio data where available may provide additional insights into suspicious activities. Applying the hybrid AI approach to new domains could also yield benefits. For example, adapting the solution for healthcare claims fraud or government benefits fraud may require domain-specific modeling of eligibility features. Another direction is developing self-- supervised learning techniques to leverage unlabeled real-- world data more effectively. This could help address the challenge of limited labeled data availability.
Conclusion
In conclusion, artificial intelligence and machine learning have emerged as promising approaches to developing next-generation financial fraud monitoring systems capable of addressing the limitations of traditional rule-based methods. The individual limitations of such techniques can be overcome by a hybrid AI solution comprising more than one model and by using the ensemble learning approach. The integration of unsupervised, supervised, and graphbased learning along with efficient preprocessing, feature engineering, and model optimization along with lifelong learning ability could lead to a highly accurate real-time fraud-detection system. In addition to the financial gains of better predictions and fewer losses for the institutions, a solution with clear operations and transparent recommendations also seeks to meet the regulatory requirement for transparency in recommendation systems and gain the users’ trust in automated decision-making. As more research is conducted to improve these complex analytical tools, fighting new and constantly emerging financial crimes is a combination of developing new technologies and collaboration between the private sector and law enforcement. The adoption of robust AI-powered monitoring systems holds the potential for strengthening protections across the entire financial ecosystem in today's era of massive digitalization and data.
- A Reurink (2019) ‘Financial Fraud: A Literature Review’, in Contemporary Topics in Finance, 1st ed., I. Claus and L. Krippner, Eds., Wiley, 79-115.
- S Gupta, SK Mehta (2021) ‘Data Mining-based Financial Statement Fraud Detection: Systematic Literature Review and Meta-analysis to Estimate Data Sample Mapping of Fraudulent Companies Against Non-fraudulent Companies’, Glob. Bus. Rev., 097215092098485.
- JM Karpoff (2021) ‘The future of financial fraud’, J. Corp. Finance, 66: 101694.
- RJ Bolton, DJ Hand, (2002) ‘Statistical fraud detection: A review’, Stat. Sci, 17: 235-55.
- M. Galeotti, G. Rabitti, E Vannucci, (2020) ‘An evolutionary approach to fraud management’, Eur. J. Oper. Res., 284: 1167-77.
- Benchaji I, Douzi S, El Ouahidi B, Jaafari J (2021) Enhanced credit card fraud detection based on attention mechanism and LSTM deep model. Journal of Big Data. 8: 1-21.
- D Dighe, S Patil, S Kokate (2018) ‘Detection of credit card fraud transactions using machine learning algorithms and neural networks: A comparative study’, in 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), IEEE, 1-6.
- I Benghazi, S Douzi, B El Ouahidi (2021) ‘Credit card fraud detection model based on LSTM recurrent neural networks’, J. Adv. Inf. Technol, 12: 2.
- J Raval et al. (2023) ‘Raksha: A trusted explainable lstm model to classify fraud patterns on credit card transactions’, Mathematics, 11: 1901.
- F Shi, C Zhao (2023) ‘Enhancing financial fraud detection with hierarchical graph attention networks: A study on integrating local and extensive structural information’, Finance Res. Lett, 58: 104458.
- S Agarwal (2023) ‘An Intelligent Machine Learning Approach for Fraud Detection in Medical Claim Insurance: A Comprehensive Study’, Sch. J. Eng. Technol, 11: 191-200.
- A Agarwal, V Gupta, Dhiraj (2021) ‘Performance Evaluation of One-Class Classifiers (OCC) for Damage Detection in Structural Health Monitoring’, in Machine Learning for Intelligent Multimedia Analytics, vol. 82, P. Kumar and A. K. Singh, Eds., in Studies in Big Data, vol. 82: 273-305.
- DM Ahmed, MM Hassan, RJ Mstafa (2022) ‘A review on deep sequential models for forecasting time series data’, Appl. Comput. Intell. Soft Comput, 2022.
- P Vijayan, Y Chandak, MM Khapra, S Parthasarathy, B Ravindran (2018) ‘Fusion Graph Convolutional Networks’. arXiv, 21.
- A Hechifa et al. (2023) ‘Improved intelligent methods for power transformer fault diagnosis based on tree ensemble learning and multiple feature vector analysis’, Electr. Eng.
- ‘TensorFlow Machine Learning Projects’. Available: https://subscription.packtpub.com/book/data/978178913221 2/2/ch02lvl1sec21/decision-tree-based-ensemble-methods
- X Zhao, L Xia, L Zou, D Yin, J Tang (2019) ‘Toward Simulating Environments in Reinforcement Learning Based Recommendations’.
- ‘Introduction to Recurrent Neural Network’, GeeksforGeeks. Available: https://www.geeksforgeeks.org/introduction-to-recurrent-neural-network/
- Barricklow, Austin (2021) "Unsupervised Machine Learning to Create Rule-Based Wire Fraud Detection." PhD diss., Utica College.
- Ali A, Abd Razak S, Othman SH, Eisa TA, Al-Dhaqm A, et al. (2022) Financial fraud detection based on machine learning: a systematic literature review. Applied Sciences. 12: 9637.
- Alarfaj FK, Malik I, Khan HU, Almusallam N, Ramzan M, Ahmed M (2022) Credit card fraud detection using state-of-the-art machine learning and deep learning algorithms. IEEE Access. 10: 39700-15.
- Li L, Wang J, Li X (2020) Efficiency analysis of machine learning intelligent investment based on K-means algorithm. Ieee Access. 8: 147463-70.
- A Ali et al. (2022) ‘Financial fraud detection based on machine learning: a systematic literature review’, Appl. Sci., 12: 9637.
- dwillis, ‘NVIDIA and bunq join forces to combat financial fraud with AI’, FinTech Global. Accessed: Jun. 05, 2024. Available: https://fintech.global/2024/06/04/nvidiaand-bunq-join-forces-to-combat-financial-fraud-with-ai/
- ‘Pan-Asian Insurance Company Improves Fraud Detection’. Accessed: Jun. 05, 2024. Available: https://www. shift-technology.com/resources/case-studies/customer-stories/pan-asian-insurance-company-improves-fraud-detection
- R Browne, (2024) ‘Mastercard jumps into generative AI race with model it says can boost fraud detection by up to 300%’, CNBC. Accessed: Jun. 05, 2024. Available: https: //www.cnbc.com/2024/02/01/mastercard-launches-gpt-- like-ai-model-to-help-banks-detect-fraud.html
- M Hassan, L AR Aziz, Y Andriansyah (2023) ‘The role artificial intelligence in modern banking: an exploration of AI-driven approaches for enhanced fraud prevention, risk management, and regulatory compliance’, Rev. Contemp. Bus. Anal, 6: 110-32.
- S Agrawal (2022) ‘Enhancing Payment Security Through AI-Driven Anomaly Detection and Predictive Analytics’, Int. J. Sustain. Infrastruct. Cities Soc, 7: 1-14.
- IH Sarker (2022) ‘AI-Based Modeling: Techniques, Applications and Research Issues Towards Automation, Intelligent and Smart Systems’, SN Comput. Sci. 3: 158.
FIGURE 1
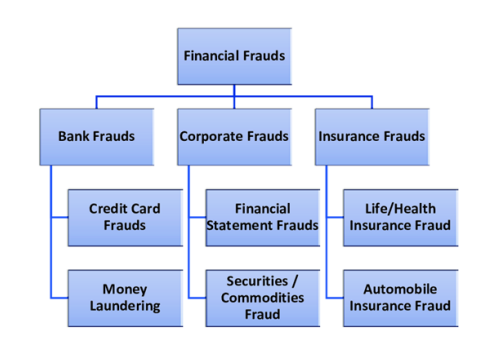
Figure 1: Types of Financial Fraud [2]
FIGURE 2
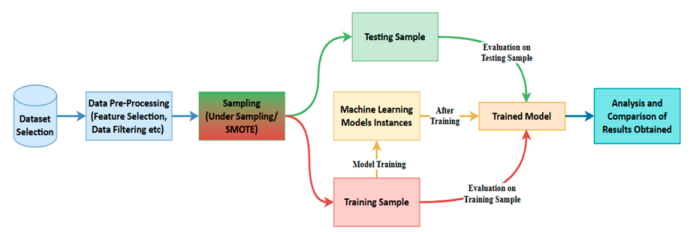
Figure 2: Machine Learning Approach for Fraud Detection [6]
FIGURE 3
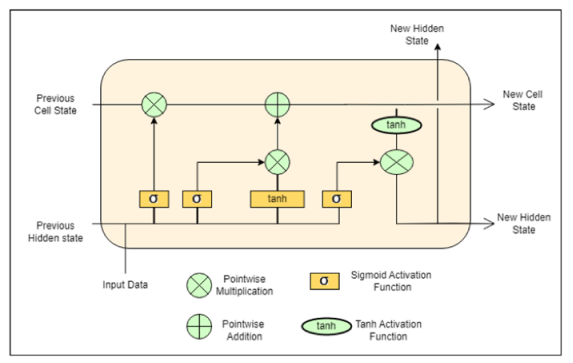
Figure 3: Long Short-Term Memory Model [9]
FIGURE 4
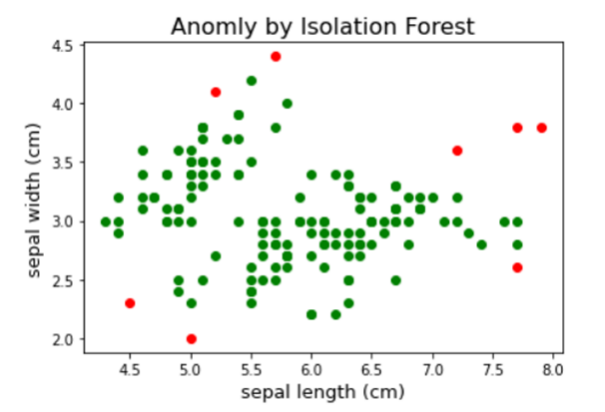
Figure 4: Anomaly Detection
FIGURE 5

Figure 5: Decision Tree Ensemble Model [16]
FIGURE 6
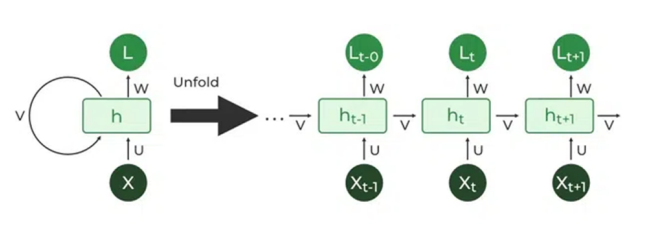
Figure 6: RNN Model [18]
Figures at a glance