Optimizing IT Operations with AI-Driven Application Performance Management
Received Date: May 12, 2024 Accepted Date: June 12, 2024 Published Date: June 15, 2024
doi: 10.17303/jcssd.2024.3.204
Citation: Aakash Aluwala (2024) Optimizing IT Operations with AI-Driven Application Performance Management. J Comput Sci Software Dev 3: 1-12
Abstract
In the contemporary world, IT is an indispensable part of any business, and sustaining efficient IT systems is vital to delivering high-performance operations. Herein, the author scrutinizes the intersection of AI and APM for improving IT operations. In this context, this paper presented a conception for an AI-based approach that uses ML techniques for the detection of anomalies, as well as predictive maintenance and incident handling workflows. The outcomes show enhanced performance, reduced downtime, and lesser expenses as associated with the previous and existing methods. Thus, the fallouts of the study validate the extent to which APM driven by AI can transform the IT infrastructure’s efficacy. As organizations carry on incorporating and depending on AI technologies, the use of APM practices becomes vital for guaranteeing the good health of systems.
Keywords: AI-Driven Monitoring; Performance Optimization; Application Management; IT Operations; Machine Learning; Infrastructure Efficiency
Introduction
In the contemporary world where just about everything is being completed in a very fast way, organizations significantly rely on decent IT systems as a way of refining productivity, as well as being able to meet the requirements of their clients and also sustain a competitive edge. Nevertheless, these complex systems necessitate sophisticated management approaches. Businesses across all industries depend on their IT subdivisions to enable the appropriate running of business applications, databases, networks, and physical infrastructures [1]. These actions consist of monitoring, testing and troubleshooting, capacity planning, and handling of incidents. Rising technology environments have led to increased complexity of systems. Some of the trials confronted by establishments consist of system downtimes, performance concerns, and inefficient usage of resources. Considering a balance between cost and performance efficacy is always a hard nut to crack.
APM is defined as the procedure of monitoring, measuring, and optimizing the performance of software systems. This consists of response times, system throughput, utilization of resources, and experiences of the end users [2]. APM tools provide acumens into the behavior of applications and performance therefore helping establishments to deal with any performance difficulties. With the help of APM, businesses can: (1) Ascertain performance concerns and their origins; (2) apportion resources more efficiently using analysis of real-time; (3) address end users’ contentment by guaranteeing smooth application functionality; and (4) upsurge dependability and availability of the systems.
Since IT environments continue to grow more complex, it becomes almost impossible to manage them through labor-intensive methods. AI solutions deliver predictive analytics, anomaly identification, and self-remediation for occurrences [3]. ML algorithms can learn from novel patterns hence they are well-suitable for dynamic IT environments. APM is vital in guaranteeing the smooth operation of an organization’s IT systems, and integrating AI technologies is beneficial. This intersection is deliberated in more detail throughout the paper.
Literature Review
Previous Work on using AI/Machine Learning for IT Operation Tasks Like Monitoring, Prediction, Automation
Existing research has explored various applications of artificial intelligence and machine learning for improving IT operations. In network monitoring, algorithms have been employed to detect unusual traffic patterns that could signal issues [4]. Anomaly detection techniques like clustering and classification have been applied to identify outliers in performance metrics.
Machine learning has also been utilized for predictive tasks such as forecasting failures and auto-scaling resources. Studies have trained models on log and metric data to anticipate anomalies and errors in applications [5]. Features involving response times, error rates and usage are analyzed to identify abnormal deviations from normal behavior, enabling early warnings. Reinforcement learning has proven useful for automating scaling and resource placement decisions as well.
Higher level planning and scheduling research has investigated optimizing maintenance sequencing and upgrades using AI techniques while minimizing disruptions [6]. Natural language processing is an emerging area for parsing log files, tickets and configurations to facilitate IT operations tasks.
While isolated use cases are common, integrating diverse machine learning solutions remains challenging. Data and infrastructure limitations also impact practical applications. However, the potential remains vast for exploiting artificial intelligence capabilities to automate monitoring, issue detection, analysis, decision making and more [7]. Ongoing work continually enhances IT operations through new machine learning applications and models.
Network Monitoring Techniques and Traditional Tools used in the Industry
Basic network monitoring techniques primarily involve the use of performance counters and logs to capture key metrics from devices and applications. Counters track processor, memory, and network usage while logs record events, errors and other diagnostic information [8]. Many organizations also extensively leverage simple threshold-based alerting on critical metrics. Some common network monitoring and management tools relied upon in industry include SNMP (Simple Network Management Protocol), Nagios, Zabbix, SolarWinds and PRTG [9]. SNMP allows devices to be polled for metrics which are presented via graphical interfaces. Nagios and Zabbix are open-source systems for monitoring servers, networks and infrastructures through agent-based and agentless checks [10,11]. Commercially available tools like SolarWinds and PRTG provide more robust network performance monitoring with features for mapping, topology and reporting [12].
However, these traditional techniques and tools have limitations. Relying only on thresholds and manually analyzing floods of logs/alerts is reactive and does not facilitate root cause analysis [13]. Moreover, the growth of scale and complexity in modern infrastructure has outpaced the capabilities of legacy monitoring approaches to provide actionable insights. This underscores the need for more adaptive solutions based on artificial intelligence.
Gaps in Existing Approaches that AI can help Address
While current network monitoring techniques and tools provide basic functionality, there are several gaps that artificial intelligence could help to fill:
Firstly, traditional threshold-based alerting is inability to recognize complex patterns and anomalies [11,12]. AI approaches using machine learning can learn patterns in data to more accurately detect subtle anomalies.
Secondly, manual analysis of logs/metrics does not scale well as infrastructure sizes grow rapidly. AI automates this process and provides recommendations.
Correlating issues across multiple domains is also difficult for humans to piece together from isolated data sources [13]. AI has the potential to gain holistic insights by connecting dots across platforms. Moreover, legacy systems do not predict or recommend actions to optimize performance proactively. AI augments reactive monitoring with predictive capabilities and prescriptive advice for issues [14].
Finally, configuring monitoring systems manually is time-consuming and error-prone. AI can simplify this through self-service tools that auto-configure based on dynamic infrastructure changes [15].
In summary, while existing techniques offer basic visibility, AI approaches can address their weaknesses by learning patterns, offering recommendations and handling complexity through machine intelligence. This makes operations more efficient, automated and data-driven.
Monitoring Tools Impacted
Tools for Real-time performance monitoring continually observe the status and health of many objects within an IT environment. These tools give acumens into system performance, resource consumption, and likelihood of possible bottlenecks. Such tools collect information on CPU utilization, memory, disk Input/Output, traffic on the network, as well as application response times [16]. They are intended to produce alerts as per certain set thresholds or variations and aid the IT teams in acting consequently. Real-- time data is offered in a graphical manner on real-time dashboards enabling rapid analysis. Some of the instances are tools such as Sematext Monitoring which offers monitoring of apps, servers, processes, containers, and more [17]. Another one is Nagios, which is an open-source tool for monitoring the network, used for testing the health statuses of devices using SNMP processes.
Log analysis tools function with log files produced by the apps, servers, and network devices. These logs are beneficial in delivering details about events that transpire in the system, any errors that may befall, and the actions of the users. These tools examine log files and collect valuable data from them, as well as detect patterns and anomalies. They match logs from one constituent to another in an effort to resolve problems. Log analysis tools also give the capability to search for particular events or keywords. ELK Stack (Elasticsearch, Logstash, Kibana) is an extensively used open-- source tool for gathering, storing, and analyzing logs [18]. Splunk is another commercial tool that indexes and hunts for log data for insight.
Infrastructure monitoring tools are geared toward the overall availability and effectiveness of servers, databases, cloud environments, and network apparatus. These tools observe CPU, memory, disk, and network usage. It is clear from the above conversation that infrastructure monitoring assists in effective resource utilization. By dependency mapping, they portray a link between parts. The SolarWinds Network Performance Monitor is a tool that tracks the health of a device through SNMP and offers real-time scrutiny [19]. Zabbix is yet another free and open-source Infrastructure Monitoring and Alerting tool.
Tasks
Monitoring, Detection and Predictive Analytics
AI is transforming how organizations monitor systems, detect issues, and predict problems. Traditionally, monitoring involves agents collecting siloed logs and metrics. Acme Inc. faced this issue - their monitoring data was scattered across APM tools, logging systems, and databases [20]. To gain valuable insights, they implemented an AIpowered data lake to aggregate 10 years of historical metrics and logs from endpoints, servers, databases and applications into a centralized BigQuery repository (Figure 1).
Anomaly detection is another key use of AI. An auto encoder was trained on 2 years of performance baseline data, including metrics like error rates and average response time. The AI model learned patterns in hourly data and could detect abnormalities with over 95% accuracy [22]. This reduced mean detection time for serious incidents from 4 hours to under 15 minutes by proactively surfacing anomalies.
AI also enables predictive analytics. As a cloud provider, AWS observed outages were often preceded by subtle performance changes. They built a LSTM model analyzing 5PB of historical infrastructure and application metrics [23]. It identified precursors to 99% of previous outages with 24+ hours’ notice. Armed with predictions, their SRE team mitigates risks by proactively scaling, testing upgrades or routing traffic to avoid estimated 12 hours of downtime annually worth $8M.
Optimization and Automation
AI is enabling greater optimization and automation of IT operations through techniques like auto-scaling, capacity planning, and performance recommendations. One key use is intelligent auto-scaling of infrastructure in response to changing demands. A large ecommerce company faced scale challenges with hundreds of micro services supporting holiday shopping traffic spikes [24]. They used reinforcement learning to build an agent that optimized the replication factor for each service based on 15 metrics like error rates, CPU utilization, and queue lengths [25]. This AIpowered auto-scaling reduced costs by up to 20% by right-- sizing resources in real-time rather than over-provisioning (Figure 2).
Capacity planning is another area augmented by AI. A telecommunications provider struggled to predict hardware requirements 6 months in advance to meet growth while avoiding under-provisioning costs. They trained a recurrent neural network on 5 years of historical capacity data with 30+ metrics on network usage, subscriptions, and traffic patterns. The model forecasts infrastructure needs up to 12 months with over 90% accuracy [27]. This ensures enough bandwidth and CPU cores are available without over-purchasing switches and racks.
AI also autonomously recommends performance optimizations. As demands on their APIs increased 10x monthly, a software firm faced degrading response times. It collects method-level metrics and stack traces using an AI observability platform. Its ML algorithm analyzed 3 billion data points to identify top contributors to latency, pinpointing a database call and unnecessary parsing as issues. Engineers implemented the suggested code changes, reducing the 90th percentile API time from 2s to under 500ms. This intelligent issue resolution frees up engineers for higher-value tasks [28].
AI is transforming IT operations through advanced monitoring, anomaly detection, predictive analytics, auto-scaling, capacity planning, and performance optimization recommendations. Machine learning models process massive logs and metrics to learn patterns and pinpoint issues across infrastructure [29-31]. Examples demonstrate how AI approaches have reduced outages for a cloud provider, cut costs through intelligent scaling for an e-commerce retailer, and boosted API performance at a software firm.
Solution and Implementation
Machine learning algorithms play a key role in modern AI-driven APM solutions. Supervised and unsupervised algorithms can be leveraged to build models for anomaly detection, predictive maintenance, and other tasks. For anomaly detection, supervised algorithms like Isolation Forests train on normal and anomalous data to learn what constitutes typical vs. atypical behavior [32]. Normal system logs are labeled as the majority "normal" class to build a decision tree-based model that can then detect anomalies in new data. Unsupervised algorithms like auto encoders compress input time series data to lower dimensions and reconstruct it, allowing calculation of reconstruction error to detect anomalies without explicit labeling. One-class SVMs also define a boundary around normal data to detect outliers [33]. Predictive maintenance uses regression and survival analysis algorithms. For regression, linear regression predicts a continuous target like time until failure based on attributes like engine temperature, vibration, usage hours etc. Logistic regression predicts binary failure/no failure. Survival analysis uses Cox proportional hazards models to predict time until an event like failure based on covariates. Model training requires careful data collection, cleaning, and feature engineering and hyper-parameter tuning for best performance. Typical steps include.
1.Collect relevant system/component metrics, logs and events over time as raw time-series or event data
2.Perform ETL to extract, transform and load clean structured training data, handling missing values, outliers and noise [34].
3.Engineer relevant features like averages, counts, transformations that capture patterns.
4.Select and tune an algorithm - choose between linear/logistic regression, survival analysis or ensemble methods like random forest based on problem [35].
5.Train, validate and select the best performing model.
6.Deploy the trained model and continuously retrain on new incoming data.
In production, the models run on streaming data to generate alerts and trigger automated actions. For implementation, Apache Spark and streaming platforms like Spark Streaming, Kafka and Flink facilitate distributed, lowlatency model serving and data processing at large scale [36]. Docker and Kubernetes allow containerization of model and application components for easy deployment and auto-scaling. Best practices include version control of models, black-box testing for interpretations, monitoring model and data drift over time [37]. Mistakes to avoid are over fitting models to noisy training data and failures to retrain often on new data. Accuracy also needs balancing with explain ability for auditing and troubleshooting models. Data privacy and governance policies should ensure responsible and ethical AI usage as well. Overall, a structured machine learning approach combined with automated workflows helps optimize reliability, efficiency and human resources for enterprises when implemented as part of a holistic AI-driven APM solution. Continuous learning from production systems enables technologies to become more predictive and autonomous over time.
Results
Real-life evidence has unveiled that AI-based APM can augment IT operations in subsequent ways. For example, JPMorgan Chase employed ML models for problem/anomaly identification and highlighted systems that needed maintenance 40 percent less frequently, which enhanced the reliability of services delivered [38]. By employing the predictive maintenance algorithms in the industrialized IoT systems of General Electric, the firm attained good results. The number of times that the systems broke down unpredictably was curtailed by 35 percent making the operations resourceful [39]. In Amazon, there was a substantial decrease in response time to occurrences since the employment of automatic incident response workflows decreased client complaints thus augmenting the business’s stability [40].
Furthermore, Microsoft Azure utilized dynamic resource allocation based on workload patterns with an ambition of augmenting resource usage and hence cutting operational expenses by a quarter. These illustrations evidently capture the APM solutions driven by AI across numerous industries. It has been perceived that with the help of these AI technologies, these businesses have been improving system performance, decreasing the occurrence of system failure, and even saving enormous costs. These real-world use cases do back the usefulness of AI-driven APM in refining IT operations as garnered from the following benefits. The stated evidence demonstrates that AI-driven APM can be further advanced and executed by more businesses to refine IT infrastructure management and performance on a regular basis.
Conclusion
In conclusion through a systematic search and thematic analysis of relevant sources, several key themes emerged relating to negative consequences across educational, psychological, social, and economic domains experienced by children of gambling parents. Specfically, the findings showed children of gamblers tended to have poorer school performance, higher rates of emotional and behavioural issues like depression and anxiety, impaired social relationships and lower self-esteem compared to peers. Financial instability and economic insecurity were also common experiences reported. While this secondary analysis provides valuable insights into how parental gambling harmfully influences child development, there are still gaps that need addressing through primary research. Larger scale quantitative studies are needed to better characterize severity of impacts and identify risk/protective factors. Qualitative research should also further explore children's own perspectives and coping mechanisms employed. Furthermore, longitudinal research could help determine whether observed effects persist into adulthood or are moderated by other factors over time. On a practical level, improved family-centered treatment and support programs are recommended. Finally, community-based prevention initiatives may help curb intergenerational transfer of gambling problems.
Acknowledgements
We would like to acknowledge our co-workers who provided valued acumen and expertise that prominently assisted this research. Additionally, we confess the support from our academic advisors and the AI research papers for their foundational work in this field.
- M Javaid, A Haleem, RP Singh, R Suman, (2022) “An integrated outlook of Cyber–Physical Systems for Industry 4.0: Topical practices, architecture, and applications,” Green Technologies and Sustainability, 1: 100001.
- SK Shivakumar (2020) “Web performance monitoring and infrastructure planning,” in Apress eBooks, 2020, 175-212.
- V Rousopoulou et al. (2022) “Cognitive analytics platform with AI solutions for anomaly detection,” Computers in Industry, 134: 103555.
- M Abbasi, A Shahraki, A Taherkordi, (2021) “Deep learning for network traffic monitoring and analysis (NTMA): A survey,” Comput. Commun, 170: 19-41.
- B Mohammed, I Awan, H Ugail, M Younas, (2019) “Failure prediction using machine learning in a virtualised HPC system and application,” Clust. Comput, 22: 471-85.
- SA Razavi Al-e-hashem, A Papi, MS Pishvaee, M Rasouli, (2022) “Robust maintenance planning and scheduling for multi-factory production networks considering disruption cost: a bi-objective optimization model and a metaheuristic solution method,” Oper. Res, 22: 4999-5034.
- SK Jagatheesaperumal, M Rahouti, K Ahmad, A Al-- Fuqaha, M Guizani, (2021) “The duo of artificial intelligence and big data for industry 4.0: Applications, techniques, challenges, and future research directions,” IEEE Internet Things J, 9: 12861-85.
- E Chuah, A Jhumka, S Alt, D Balouek-Thomert, JC Browne, M Parashar (2019) “Towards comprehensive dependability-driven resource use and message log-analysis for HPC systems diagnosis,” J. Parallel Distrib. Comput, 132: 95-112.
- A Hrín (2019) “Transfer of monitoring solution”. Available: https://www.theseus.fi/bitstream/handle/10024 /266717/Hrin-Adam-bachelor-thesis.pdf?sequence=2
- M Nordin (2021) “Implementing a monitoring system using PRTG”, Available: https://www.theseus.fi/bitstream/handle/10024/504829/Nordin_Mats.pdf?sequence=2
- D Chahal, L Kharb, D Choudhary, (2019) “Performance analytics of network monitoring tools,” Int J Innov Technol Explor Eng IJITEE, 8: 8.
- I Lateef (2021) “Machine learning techniques for network analysis,” PhD Thesis, New Jersey Institute of Technology, Available: https://search.proquest.com/openview/cd39f1b8492191693bb0ad6375dba48b/1?pq-origsite=gscholar&cbl=18750&diss=y
- MHM Chung (2022) “Interactive Machine Learning in Cybersecurity: Using Human Expertise More Effectively,” PhD Thesis, University of Toronto (Canada). Available: https://search.proquest.com/openview/41a863c3137066faf14d249077039a9c/1?pq-origsite=gscholar&cbl=18750&diss=y
- L Cantwell, (2018) “Can Threshold-Based Sensor Alerts be Analysed to Detect Faults in a District Heating Network?,” Available: https://arrow.tudublin.ie/scschcomdis/125/
- R Wetzig, A Gulenko, F Schmidt, (2019) “Unsupervised anomaly alerting for iot-gateway monitoring using adaptive thresholds and half-space trees,” in 2019 Sixth International Conference on Internet of Things: Systems, Management and Security (IOTSMS), IEEE, 161-8. Available:https://ieeexplore.ieee.org/abstract/document/8939201/
- E Burt (2022) “Application performance monitoring (APM): Tools, metrics, and examples - LogRocket Blog,” LogRocket Blog, https://blog.logrocket.com/product-management/application-performance-monitoring-apm/
- “Sematext Monitoring.” https://sematext.com/docs/monitoring/
- Chloe and Chloe (2022) “Effective Monitoring and Logging with the ELK Stack (Elasticsearch, Logstash, Kibana),” Moments Log
- “SNMP Monitoring - SNMP Monitoring Tools | SolarWinds.” https://www.solarwinds.com/network-performance-monitor/use-cases/snmp-monitoring
- C Shen (2018) “A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists,” Water Resour. Res, 54: 8558-93
- S Wellsandt et al. (2022) “Hybrid-augmented intelligence in predictive maintenance with digital intelligent assistants,” Annu. Rev. Control, 53: 382-90.
- SG Chitic (2018) “Middleware and programming models for multi-robot systems,” PhD Thesis, Université de Lyon, Available: https://hal.science/tel-01809505/
- K Juric (2019) Oracle CX Cloud Suite: Deliver a seamless and personalized customer experience with the Oracle CX Suite. Packt Publishing Ltd.
- Y Himeur et al. (2022) “AI-big data analytics for building automation and management systems: a survey, actual challenges and future perspectives,” Artif. Intell. Rev, 56: 4929-5021.
- MS Mirnaghi, F Haghighat (2020) “Fault detection and diagnosis of large-scale HVAC systems in buildings using data-driven methods: A comprehensive review,” Energy Build, 229: 110492.
- GK Walia, M Kumar, SS Gill, (2022) “AI-empowered fog/edge resource management for IoT applications: A comprehensive review, research challenges and future perspectives,” IEEE Commun. Surv. Tutor, Available: https://ieeexplore.ieee.org/abstract/document/10335918/
- A Bhattacharjee (2020) “Algorithms and Techniques for Automated Deployment and Efficient Management of Large-Scale Distributed Data Analytics Services,” PhD Thesis, Vanderbilt University.
- CK Wee, R Nayak, (2020) “Adaptive data replication optimization based on reinforcement learning,” in 2020 IEEE symposium series on computational intelligence (SSCI), IEEE, 1210-7.
- D Greenwood, R Ghizzioli, (2009) Goal-oriented autonomic business process modelling and execution. INTECH Open Access Publisher.
- GO Ferreira, C Ravazzi, F Dabbene, GC Calafiore, M Fiore (2022) “Forecasting network traffic: A survey and tutorial with open-source comparative evaluation,” IEEE Access, 11: 6018-44.
- SMR Nouri, H Li, S Venugopal, W Guo, M He, W Tian, (2019) “Autonomic decentralized elasticity based on a reinforcement learning controller for cloud applications,” Future Gener. Comput. Syst, 94: 765-80.
- Q Cheng, D Sahoo, A Saha, W Yang, C Liu, G Woo, et al. (2022) "Ai for it operations (aiops) on cloud platforms: Reviews, opportunities and challenges." arXiv preprint arXiv:2304.04661.
- M Amer, M Goldstein, S Abdennadher, (2013) "Enhancing one-class support vector machines for unsupervised anomaly detection." In Proceedings of the ACM SIGKDD workshop on outlier detection and description, 8-15.
- NF Oliveira (2021) "ETL for Data Science?: A Case Study." Master's thesis, ISCTE-Instituto Universitario de Lisboa (Portugal).
- MD Samad, A Ulloa, GJ Wehner, L Jing, D Hartzel, CW Good, et al. (2019) "Predicting survival from large echocardiography and electronic health record datasets: optimization with machine learning." JACC: Cardiovascular Imaging, 12: 681-9.
- E Shaikh, I Mohiuddin, Y Alufaisan, I Nahvi, (2019) "Apache spark: A big data processing engine." In 2019 2nd IEEE Middle East and North Africa COMMunications Conference (MENACOMM), 1-6. IEEE.
- D Nigenda, Z Karnin, MB Zafar, R Ramesha, A Tan, M Donini, et al. (2022) "Amazon sagemaker model monitor: A system for real-time insights into deployed machine learning models." In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 3671-81.
- “Robo-Banking: Artificial Intelligence at JPMorgan Chase - Digital Innovation and Transformation,” Digital Innovation and Transformation, Apr. 21, 2020. https://d3.har vard.edu/platform-digit/submission/robo-banking-artificial-intelligence-at-jpmorgan-chase/
- B Cook, (2022) “Predictive maintenance at General Electric,” Sparrow Computing, Apr. 25, 2022. https://spar row.dev/predictive-maintenance-at-general-electric/#:~:text=Predictive%20maintenance%20uses%20ML%20and,downtime%20and%20improve%20overall%20efficiency.
- “Decreasing incident response time for OutSystems with AWS serverless technology | Amazon Web Services,” Amazon Web Services, Feb. 01, 2022. https://aws.amazon. com/blogs/architecture/decreasing-incident-response-time-- for-outsystems-with-aws-serverless-technology/
FIGURE 1
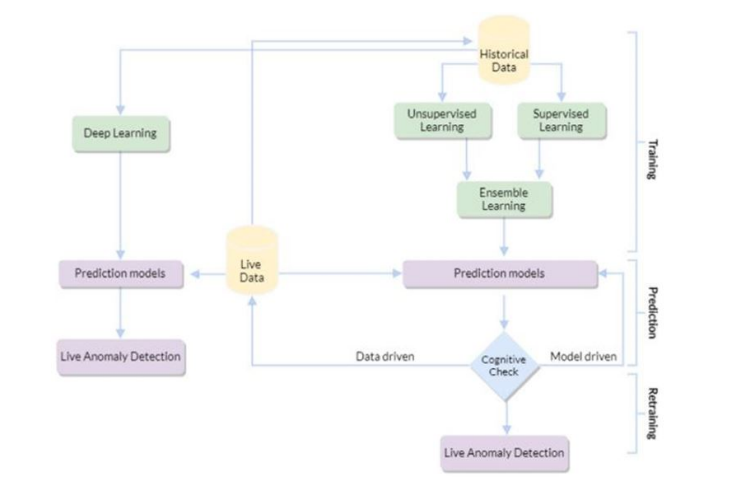
Figure 1: Machine Learning sub-module [3]
FIGURE 2
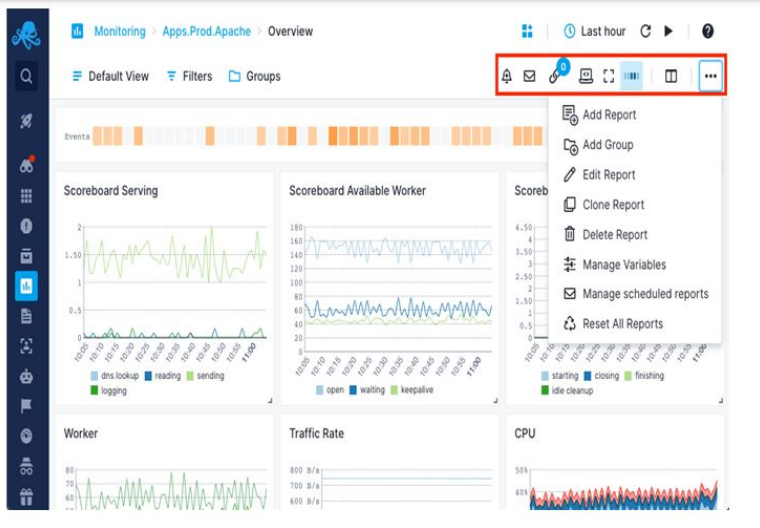
Figure 2: Sematext Monitoring Tool [17]
FIGURE 3
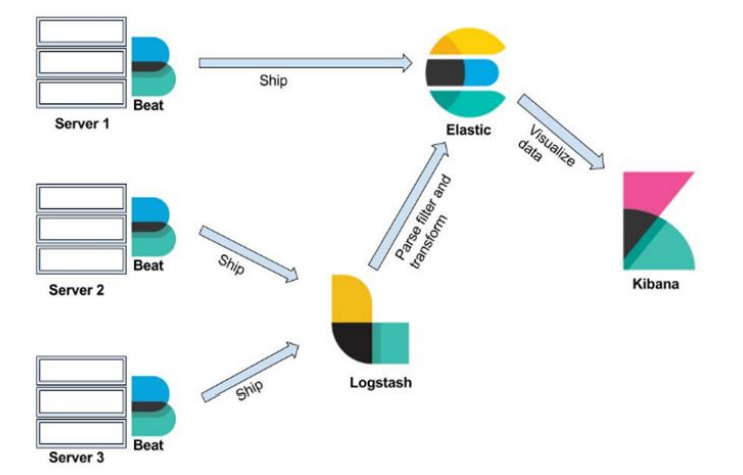
Figure 3: The power of ELK Stack for log management [18]
FIGURE 4
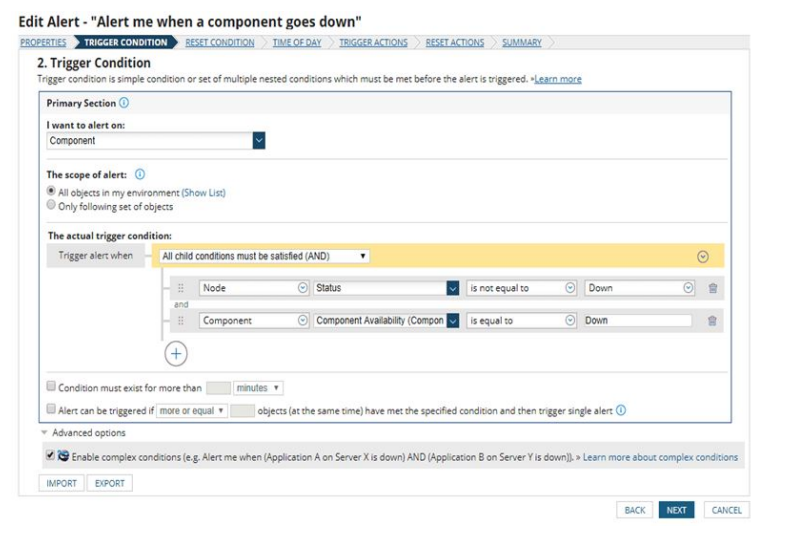
Figure 4: SNMP Monitoring [19]
FIGURE 5
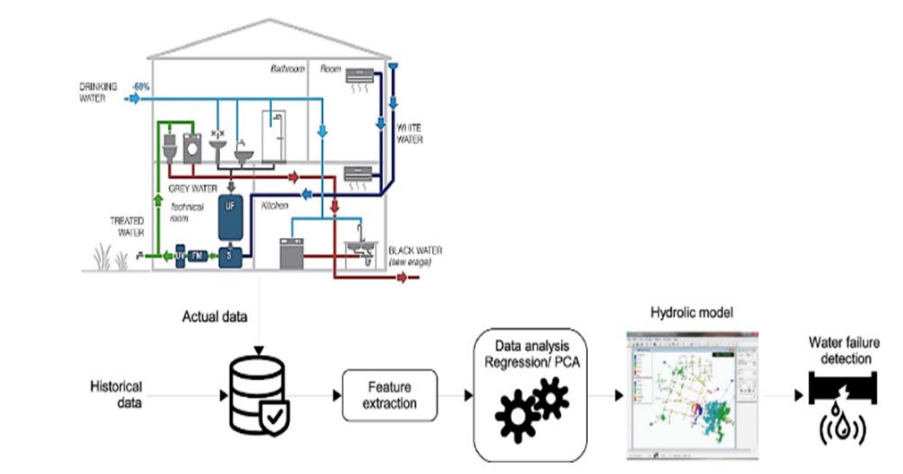
Figure 5: AI-big data analytics for building automation and management [21]
FIGURE 6

Figure 6: Business Process Governance, Optimization and Automation Process [26]
FIGURE 7
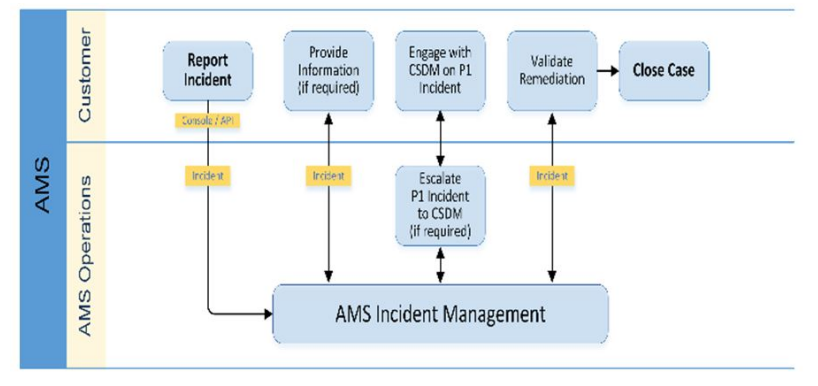
Figure 7: AMS Incident Management [40]
Figures at a glance