The Practical Applications of Retrieval-Augmented Generation in AI
Received Date: August 07, 2024 Accepted Date: September 07, 2024 Published Date: September 10, 2024
doi: 10.17303/jcssd.2024.3.205
Citation: Mounika Kothapalli (2024) The Practical Applications of Retrieval-Augmented Generation in AI. J Comput Sci Software Dev 3: 1-8
Abstract
Retrieval-Augmented Generation (RAG) represents a revolution within the field of AI, with combination of the expertise from large language models and the benefits from dynamic information retrieval. This paper looks at practical applications of RAG across domains to prove its transformative potential. The paper looks at how RAG improves customer service through intelligent chatbots, improves the accuracy of search engines, and has started to revolutionize content generation for marketing and beyond. Improved accuracy, an enriched user experience, and cost savings are a few of the many benefits that come with RAG, which this paper elaborates upon. As with each coin, there are two sides; RAG does come with various disadvantages alongside its advantages. This paper covers technical hurdles, data privacy concerns, and potential bias in retrieving data. While these pose challenges, the future is promising as emerging trends lean towards multimodal capabilities with adaptive techniques for retrieval. This comprehensive overview provides a useful understanding of the current state of RAG and what it might achieve in shaping the future of AI applications. Among the current shifts in AI, RAG is coming out to be one of the major drivers in driving us toward more intelligent, efficient, and context-aware systems.
Keywords: Retrieval-Augmented Generation; Artificial Intelligence; Natural Language Processing; Chatbots; Search Engines; Content Generation; Data Privacy; AI Ethics
Introduction
Artificial Intelligence (AI) has been evolving since its inception in 1950s. In recent years, there has been significant achievements in natural language processing (NLP) with large language models (LLMs) like GPT-3, Claude-3, Llama-3 exhibiting unprecedented capabilities in generative AI [1].
However, despite the advancements that large language models provide, there are limitations in terms of producing accurate and latest information by these models. This is mainly due to the data that is used for training is static in nature and is not updated. In order to address this Retrieval-Augmented Generation (RAG) combines the power of large language models with the ability to retrieve and incorporate external information, offering a more flexible and up-to-date approach to AI-driven text generation [2]. This paper will explore capabilities of RAG in terms of addressing such limitations.
RAG retrieves information from a knowledge base or external sources and uses it to augment the context provided to a language model in order to drive generation. In this way, the model accesses current and relevant information, which is beyond the availability of its training data, hence improving the accuracy and relevance of its outputs [3].
Purpose and ScopeThis paper aims to provide a comprehensive review of practical applications of RAG across different domains. The paper will review how RAG is implemented in customer service, search engines, and content generation, among other areas. I analyze real examples and case studies that show the benefits, challenges, and prospects of this new way through which AI is being done, in contrast to the traditional approach.
Knowing the capabilities and implications of RAG is important while AI is being integrated in daily life and business operation more and more. This paper tries to provide an overview of the status of RAG and its potential toward building the future of AI applications.
Literature Review
Previous Work on using AI/Machine Learning for IT Operation Tasks Like Monitoring, Prediction, Automation
Steps Involved in RAG
a) Retrieval: The first step is to retrieve relevant information from a knowledge base, or an external corpus based on the given query or prompt. Such retrieval is normally conducted via dense vector representations of both the query and the stored documents, which enables efficient semantic search.
b) Generation: The retrieved information is subsequently used to augment the input fed to a large language model. Equipped with this augmented context, apart from being factually grounded in the retrieved information, it generates responses that are coherent and fluent [3].
The retrieval-generator approach has several advantages as shown in Figure 1. First, it enables access to and use of extra information that the model has not seen before, potentially reducing hallucinations and increasing the accuracy of the facts. Second, this provides some degree of transparency regarding the sources of information, which can be traced back to the retrieval step. Finally, this enables the development of more flexible and adaptable AI—without the need for total retraining of the entire model [4].
Practical Applications of RAG
RAG has found different applications within different industries as illustrated in Figure 2, offering improvements in AI capabilities such as in customer support, search engines, and content generation.
A. Customer Service
RAG technology has profited heavily in terms of chatbots and virtual assistants. Here, the combination of retrieval from company knowledge bases and natural language generation makes this AI agent more accurate and contextually relevant to answer customer queries [5].
In real-world applications, RAG is used by IBM's Watson Assistant to enhance real-time customer conversations by fetching relevant information from the company databases. The responses would be more accurate and contextually relevant, given the fact that it pertains more to what the customers are asking [6].
Salesforce's Einstein, for instance, embeds RAG to improve its ability to assist customer service representatives by providing relevant information and suggested responses [7].
B.Search Engines
It has also enhanced the search by improving relevance and accuracy in the results. Thus, one of the significant strengths a search engine has with RAG at its core is returning relevant information and creating informative snippets that are concise enough to be shown to the user.
Case studies include the following: Models like Google BERT and MUM, which also apply RAG-like methods to understand context for more relevant answers in search [8].
Microsoft's Bing Chat blends web search with generative AI to provide more interactive and informative search experiences [9].
C.Content Generation
In the field of marketing and content creation, quality, fact-based content became possible with the development of sophisticated tools by RAG.
Examples of businesses that have made use of RAGs in content creation include the following:
OpenAI's GPT-3, which can be used with RAG to produce more relevant and updated content as and when needed in several kinds of use cases.
Jasper.ai: Uses RAG to create marketing copies, blog posts, and many other content types based on information that is available at the moment and user inputs [10].
These practical applications give an idea that how RAG can be used in a variety of scenarios. This, in general, is promising for the potential AI would have to benefit a broad range of other industries than NLP, as it could feed more accurate, relevant, and up-to-date information to users.
Practical implications of RAG are not restricted to only customer service or content generation. In some other domains, like healthcare, legal, and finance, RAG may cause a simple difference in how professionals themselves interact with data to give more relevant and updated insights without time-consuming manual research. Applications in the future might also see RAG integrated into real-time decision-support systems, where its ability to provide precise, tailored data is likely to be one of the leading sources of operational efficiency.
Benefits of RAF
RAG offers several significant advantages over traditional language models.
A. Accuracy and Efficiency
RAG models are more accurate because of their retrieved information is from latest sources. This approach significantly reduces the possibility of generating false or obsolete information, which is often the case with standard language models. Accurate and factual responses can be given, especially on knowledge-intensive tasks, by retrieving from external knowledge bases. In addition, RAG will be able to access relevant information efficiently through its retrieval mechanism and improve the system's efficiency in general [2].
B. Enhanced User Experience
As RAG offers informative, contextually relevant, and up-to-date responses. For applications like chatbots or virtual assistants, this means more natural and helpful interactions. This would provide more complete and accurate results in the case of search engines, thereby eliminating the need for multiple queries [11].
C. Cost Savings and Scalability
In contrast with the continuous retraining of large language models, RAG offers both significant cost savings and improved scalability. If an organization separates the knowledge base from the language model, then it can update any kind of information without having to frequently retrain the model, which involves a lot of resources. Having this separation makes scaling up easier because the knowledge base may be expanded or otherwise altered independently of the language model. This, in turn, likely means that RAG systems are more accurate to require less human intervention in tasks like customer support, which would further contribute to cost savings.
The added advantage in flexibility and cost comes from the fact that retrieval is tuned for a particular domain or application. It means that an organization can also ensure that it personalizes its knowledge base to suit its needs in terms of relevance and accuracy, probably bringing down the size and complexity of the required language model [3].
All these advantages, place RAG as one of the strong and effective approaches to develop more accurate, more user-friendly, and cost-effective AI systems across different applications.
Challenges and Limitations
Retrieval-Augmented Generation also comes with some challenges and limitations as shown in Table 1.
A. Technical Challenges
One of the biggest challenges faced by RAG systems is to find a balance between retrieval accuracy and computational efficiency, especially when the knowledge base is huge and complicated. Advanced indexing techniques and mechanisms for error correction are therefore being developed. Another critical concern involves data privacy. RAG systems operating over large data sets may inadvertently retrieve personal data. This risk is greatly minimized by the presence of encryption and stringent access controls. Finally, there is algorithmic bias inherent in AI systems. Possible detection of biased algorithms and diverse training datasets could be a balance to this issue [5].
Technical challenges include how to propagate the retrieval error through the system. For example, if the retriever component returns irrelevant or inaccurate information, then it might result in a generation model that produces outputs that are misleading or make no sense. In this process, developing robust error detection and correction mechanisms is needed [3].
B. Data Privacy and Security Concerns
Most of the time, RAG systems work over very large amounts of data. This could open various issues concerning privacy and security, since the process of retrieval may result in the involuntary exposition of sensitive information. Another issue would be the vulnerability to data poisoning attacks: malicious parties would be able to inject false or harmful information into the knowledge base.
C. Potential Biases
Like other AI systems, RAG might also inherit certain biases from training data and knowledge bases on gender, race, culture, geographical skews in the information retrieved, among others. This sets up the possibility of unfair or discriminatory outputs and serves to reinforce certain biases.
It is, therefore, of essence that RAG systems have some sort of bias detection and mitigation through continuous monitoring and adjustments where necessary. There is a need to ensure not just that data representation is diverse but also that the output coming out of the system must regularly be audited for any potential biases [12].
While these challenges are huge, continuous research and development in the domain of RAG are trying to get rid of these limitations with consistency, and thereby ways towards more robust, secure, and unbiased systems will be opened up in times to come.
Future Trends
A. Emerging Trends
The field of RAG is rapidly evolving with many emerging trends such as:
1) Multi-modal RAG:Some work is ongoing to go beyond the text which includes images, audio, and video [13].
2) Adaptive retrieval: It has been envisaged that next-generation RAG may include possible retrieval strategies whose activation depends on task being performed, thereby increasing the efficiency and relevance at hand [14].
3) Explainable RAG: There is a growing need for RAG systems to transparently show the source of a response, if one is generated.
B. Possible Improvements and Innovations
From a future development perspective, several improvements can vastly improve RAGs:
1) Improved retrieval algorithms: Semantic Search and Knowledge Graph are two active areas of research that can lead to more accurate, higher-speed retrieval.
2) Real-time knowledge updates:Future RAG systems can execute a cycle of real-time updates to the knowledge base so that the most current reflection is maintained.
3) Personalization of RAG: By preference, levels of expertise, and domain-specific knowledge, so will systems be tailored to their users or organizations [15].
Conclusion
Retrieval Augmented Generation (RAG) combines the power of information retrieval and language generation. I have illustrated several applications in customer service, search engines, and content generation. Additionally explained the advantages accruable from this, such as improved accuracy, enhanced user experience, and cost savings. However, I also accept the challenges that exist on the side of technical difficulties, privacy concerns, and bias.
The RAG also contributes a great deal to the roadmap relating to more reliable, informative, and context-aware AI systems. Based on grounding language generation in retrieved information, RAG mitigates some of the fundamental limitations associated with traditional language models on issues of hallucination and outdated knowledge.
With further evolution, RAG is going to dramatically change the way AI is used in a lot of domains. From smarter virtual assistants to more relevant and useful search engines, RAG is opening the way for AI systems to provide users with more valuable and trustworthy information.
Full realization of RAG will only be possible when research continues to overcome the limitations and ethical considerations that best describe it. In the future, RAG systems shall have to be developed with power and efficiency but also transparency, fairness, and privacy in mind.
This places Retrieval-Augmented Generation as a very promising direction in AI research and application. Continuing in the advancement, RAG is likely to continue playing a very important role in shaping the future of AIpowered information systems toward truly intelligent and helpful artificial intelligence [5].
- TB Brown et al. (2020) "Language Models are FewShot Learners," in Advances in Neural Information Processing Systems.
- P Lewis et al. (2020) "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," in Advances in Neural Information Processing Systems.
- K Guu et al. (2020) "REALM: Retrieval-Augmented Language Model Pre-Training," arXiv preprint arXiv: 08909.
- A Borgeaud et al. (2022) "Improving language models by retrieving from trillions of tokens," in International Conference on Machine Learning.
- Y Sun et al. (2023) "A Survey of Retrieval-Augmented Text Generation," arXiv preprint arXiv: 2302-00384.
- IBM, "Watson Assistant," [Online]. Available: https://www.ibm.com/products/watson-assistant.
- Salesforce, "Einstein for Service," [Online]. Available: https://www.salesforce.com/products/service-cloud/einsteinfor-service/.
- A Tay et al. (2023) "Efficient Large Language Models: A Survey," arXiv preprint arXiv: 2302-06117.
- Microsoft, "Introducing the new Bing," [Online]. Available: https://www.bing.com/new.
- Jasper, "AI Content Platform," [Online]. Available:https://www.jasper.ai/.
- J Thoppilan et al. (2022) "LaMDA: Language Models for Dialog Applications," arXiv preprint arXiv: 2201-08239.
- EM Bender et al. (2021) "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
- A Karpathy (2023) "Introducing GPT-4V (Vision)," OpenAI Blog, 2023. [Online]. Available: https://openai.com/blog/chatgpt-can-now-see-hear-and-speak.
- J Ni et al. (2023) "Adaptive Retrieval-Augmented Language Models," arXiv preprint arXiv: 2309-09545.
- S Zhang et al. (2023) "Personalized Retrieval-Augmented Language Models," in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval.
FIGURE 1
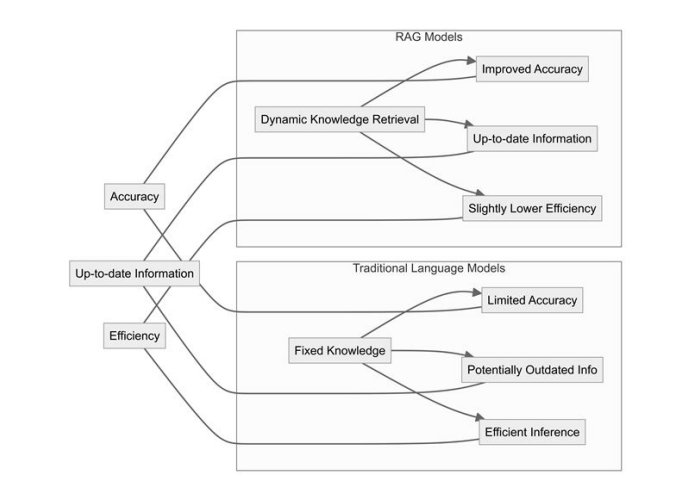
Figure 1: Comparison between traditional language models and RAG models
FIGURE 2
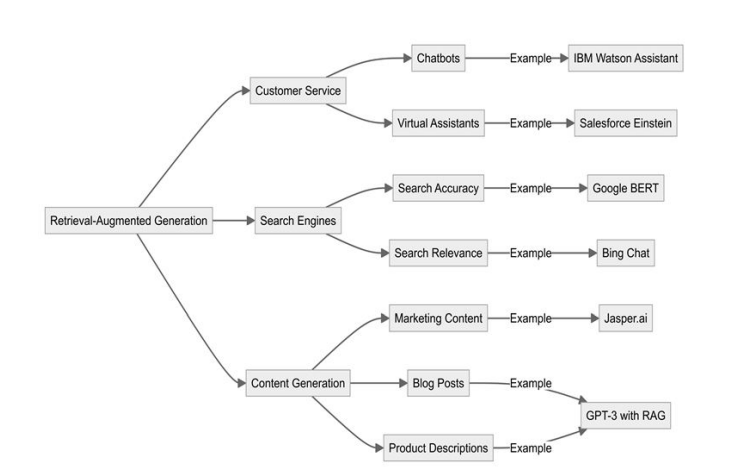
Figure 2: RAG applications
Tables at a glance
Figures at a glance